인프런 김영한 강의와 자료를 토대로 부분적으로 요약했단 점 참고바랍니다.
앞 글에서 좋은 객체 지향 설계의 원칙 5가지(SOLID)를 지키기 위해 역할(인터페이스)과 구현(클래스)을 분리했다.
그렇지만 구현체를 바꿀 때 마다 코드 수정으로 인해 OCP 위반과 구현체(클래스)에 의존하므로 DIP 위반을 일어난다.
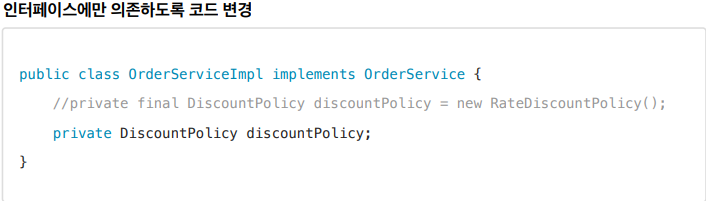
DIP를 지키기 위해 위 처럼 코드를 변경한다 하더라도 구현체가 없으므로 NPEE(null pointer exception)가 발생한다.
이 문제를 해결하기 위해 관심사를 분리한다.

구현 객체를 생성하고, 연결하는 책임을 가지는 별도의 설정 클래스(AppConfig)를 만들면 생성자를 통해 주입해줘
OCP와 DIP를 지킬 수 있다.
IoC, DI, 컨테이너
제어의 역전 IoC(Inversion of Control)
기존 프로그램은 클라이언트 구현 객체가 스스로 필요한 서버 구현 객체를 생성하고, 연결하고, 실행했다. 한마디로 구현 객체가 프로그램의 제어 흐름을 스스로 조종했다. 반대로 프로그램의 제어 흐름을 직접 제어하는 것이 아니라 외부에서 관리하는 것을 제어의 역전(IoC)이라 한다.
프레임워크가 내가 작성한 코드를 제어하고, 대신 실행하면 그것은 프레임워크가 맞다. (JUnit) 반면에 내가 작성한 코드가 직접 제어의 흐름을 담당한다면 그것은 프레임워크가 아니라 라이브러리다.
DI(의존관계 주입)
애플리케이션 실행 시점(런타임)에 외부에서 실제 구현 객체를 생성하고 클라이언트에 전달해서 클라이언트와 서버의 실제 의존관계가 연결 되는 것을 의존관계 주입이라 한다. 의존관계 주입을 사용하면 정적인 클래스 의존관계를 변경하지 않고, 동적인 객체 인스턴스 의존관계를 쉽게 변경할 수 있다.
DI 컨테이너
AppConfig 처럼 객체를 생성하고 관리하면서 의존관계를 연결해 주는 것을 IoC 컨테이너 또는 DI 컨테이너라 한다.
스프링 사용


스프링 컨테이너는 빈을 생성하고 생성한 빈을 통해 알아서 의존관계 주입을 해줄 뿐만 아니라 싱글톤 객체를 생성하고 관리하는 기능이 있어 싱글톤 패턴의 모든 단점을 해결하면서 객체를 싱글톤으로 유지할 수 있다.
-> 객체 공유를 통해 효율적으로 재사용
위 코드에는 memberRepostory()가 중복되어 각각 다른 객체 3개가 생성되는 것처럼 보이지만 스프링 컨테이너는 이미 해당 클래스 객체가 있다면 컨테이너에서 찾아서 쓰므로 싱글톤이 보장된다.
싱글톤 방식의 주의점
여러 클라이언트가 하나의 객체를 공유하므로 무상태(stateless)로 설계해야 한다.
- 특정 클라이언트에 의존적인 필드가 있으면 안된다.
- 특정 클라이언트가 값을 변경할 수 있는 필드가 있으면 안되고 가급적 읽기만 가능해야 한다.
- 필드 대신에 자바에서 공유되지 않는, 지역변수, 파라미터, ThreadLocal 등을 사용해야 한다.
의존관계 자동 주입(@ComponentScan, @Component) vs 의존관계 수동 주입(@Configration, @Bean)
@ComponetScan이 있는 클래스가 속한 패키지를 기준으로 @Component가 있는 클래스와 @Configration이 있는 클래스(@Component를 포함)를 스프링 컨테이너에 빈 등록하고 의존관계를 주입해준다.
@Configration가 있는 클래스(해당 객체도 스프링 빈으로 등록됨)를 스프링 컨테이너에 등록하면 싱글톤을 유지해주고 @Bean을 통해 스프링 빈으로 등록된다.
자동 빈 등록과 수등 빈 등록 언제 사용해야 할까?
업무 로직 빈: 웹을 지원하는 컨트롤러, 핵심 비즈니스 로직이 있는 서비스, 데이터 계층의 로직을 처리하는 리포지토리등이 모두 업무 로직이다. 보통 비즈니스 요구사항을 개발할 때 추가되거나 변경된다.
기술 지원 빈: 기술적인 문제나 공통 관심사(AOP)를 처리할 때 주로 사용된다. 데이터베이스 연결이나, 공통 로그 처리 처럼 업무 로직을 지원하기 위한 하부 기술이나 공통 기술들이다.
스프링 부트의 경우 DataSource 같은 데이터베이스 연결에 사용하는 기술 지원 로직까지 내부에서 자동으로 등록하는데, 이런 부분은 메뉴얼을 잘 참고해서 스프링 부트가 의도한 대로 편리하게 사용하면 된다. 반면에 스프링 부트가 아니라 내가 직접 기술 지원 객체를 스프링 빈으로 등록한다면 수동으로 등록해서 명확하게 드러내는 것이 좋다.
-> 편리한 자동 기능을 기본으로 사용하자 직접 등록하는 기술 지원 객체는 수동 등록 다형성을 적극 활용하는 비즈니스 로직은 수동 등록을 고민해보자
컴포넌트 스캔 기본 대상
@Component : 컴포넌트 스캔에서 사용
@Controlller : 스프링 MVC 컨트롤러에서 사용
@Service : 스프링 비즈니스 로직에서 사용
@Repository : 스프링 데이터 접근 계층에서 사용
@Configuration : 스프링 설정 정보에서 사용
다양한 의존관계 주입
생성자 주입, 수정자 주입(setter 주입), 필드 주입, 일반 메서드 주입으로 4가지 방법이 있다.
결과적으로 생성자 주입을 선택해라.
- 생성자 주입 방식을 선택하는 이유는 여러가지가 있지만, 프레임워크에 의존하지 않고, 순수한 자바 언어의 특징을 잘 살리는 방법이기도 하다.
- 기본으로 생성자 주입을 사용하고, 필수 값이 아닌 경우에는 수정자 주입 방식을 옵션으로 부여하면 된다. 생성자 주입과 수정자 주입을 동시에 사용할 수 있다.
- 항상 생성자 주입을 선택해라! 그리고 가끔 옵션이 필요하면 수정자 주입을 선택해라. 필드 주입은 사용하지 않는게 좋다.
조회 빈이 2개 이상일 때 문제 - @Autowired 필드 명, @Qualifier, @Primary
조회 대상 빈이 2개 이상일 때 해결 방법
@Autowired 필드 명 매칭 : 선호 X
@Qualifier -> @Qualifier끼리 매칭 -> 빈 이름 매칭 : 추가 구분자를 붙여주는 방법
@Primary 사용 : 해당 어노테이션이 있는 빈이 우선순위
@Primary, @Qualifier 활용
코드에서 자주 사용하는 메인 데이터베이스의 커넥션을 획득하는 스프링 빈이 있고, 코드에서 특별한 기능으로 가끔 사용하는 서브 데이터베이스의 커넥션을 획득하는 스프링 빈이 있다고 생각해보자. 메인 데이터베이스의 커넥션을 획득하는 스프링 빈은 @Primary 를 적용해서 조회하는 곳에서 @Qualifier 지정 없이 편리하게 조회하고, 서브 데이터베이스 커넥션 빈을 획득할 때는 @Qualifier 를 지정해서 명시적으로 획득 하는 방식으로 사용하면 코드를 깔끔하게 유지할 수 있다. 물론 이때 메인 데이터베이스의 스프링 빈을 등록할 때 @Qualifier 를 지정해주는 것은 상관없다
@Qualifier이 @Primary 보다 우선권이 높다.
빈 생명주기 콜백
시작 데이터베이스 커넥션 풀이나, 네트워크 소켓처럼 애플리케이션 시작 시점에 필요한 연결을 미리 해두고, 애플리케이션 종료 시점에 연결을 모두 종료하는 작업을 진행하려면, 객체의 초기화와 종료 작업이 필요하다.
스프링 빈은 객체를 생성하고, 의존관계 주입이 다 끝난 다음에야 필요한 데이터를 사용할 수 있는 준비가 완료된다. 따라서 초기화 작업은 의존관계 주입이 모두 완료되고 난 다음에 호출해야 한다. 그런데 개발자가 의존관계 주입이 모두 완료된 시점을 어떻게 알 수 있을까?
스프링은 의존관계 주입이 완료되면 스프링 빈에게 콜백 메서드를 통해서 초기화 시점을 알려주는 다양한 기능을 제공한다. 또한 스프링은 스프링 컨테이너가 종료되기 직전에 소멸 콜백을 준다. 따라서 안전하게 종료 작업을 진행할 수 있다.
참고: 객체의 생성과 초기화를 분리하자.
생성자는 필수 정보(파라미터)를 받고, 메모리를 할당해서 객체를 생성하는 책임을 가진다. 반면에 초기화는 이렇게 생성된 값들을 활용해서 외부 커넥션을 연결하는등 무거운 동작을 수행한다.
따라서 생성자 안에서 무거운 초기화 작업을 함께 하는 것 보다는 객체를 생성하는 부분과 초기화 하는 부분을 명확하게 나누는 것이 유지보수 관점에서 좋다. 물론 초기화 작업이 내부 값들만 약간 변경하는 정도로 단순한 경우에는 생성자에서 한번에 다 처리하는게 더 나을 수 있다.
빈 생명주기 콜백 지원 방법
- 인터페이스(InitializingBean, DisposableBean)
- 설정 정보에 초기화 메서드, 종료 메서드 지정
- @PostConstruct, @PreDestroy 애노테이션 지원
정리
@PostConstruct, @PreDestroy 애노테이션을 사용하자. 코드를 고칠 수 없는 외부 라이브러리를 초기화, 종료해야 하면 @Bean 의 initMethod , destroyMethod 를 사용하자
빈 스코프
스코프 : 스코프는 번역 그대로 빈이 존재할 수 있는 범위를 뜻한다.
스프링은 다음과 같은 다양한 스코프를 지원한다.
싱글톤: 기본 스코프, 스프링 컨테이너의 시작과 종료까지 유지되는 가장 넓은 범위의 스코프이다.
프로토타입: 스프링 컨테이너는 프로토타입 빈의 생성과 의존관계 주입까지만 관여하고 더는 관리하지 않는 매우 짧은 범위의 스코프이다.
웹 관련 스코프
- request: 웹 요청이 들어오고 나갈때 까지 유지되는 스코프이다.
- session: 웹 세션이 생성되고 종료될 때 까지 유지되는 스코프이다.
- application: 웹의 서블릿 컨텍스트와 같은 범위로 유지되는 스코프이다.
싱글톤 빈을 조회하면 스프링 컨테이너는 항상 같은 인스턴스의 스프링 빈을 반환한다. 반면에 프로토타입 스코프는 스프링 컨테이너는 항상 새로운 인스턴스를 생성해서 반환한다!
정리
여기서 핵심은 스프링 컨테이너는 프로토타입 빈을 생성하고, 의존관계 주입, 초기화까지만 처리한다는 것이다. 클라이언트에 빈을 반환하고, 이후 스프링 컨테이너는 생성된 프로토타입 빈을 관리하지 않는다. 프로토타입 빈을 관리할 책임은 프로토타입 빈을 받은 클라이언트에 있다. 그래서 @PreDestroy 같은 종료 메서드가 호출되지 않는다.
프로토타입 빈 활용
프로토타입 빈을 언제 사용할까? 매번 사용할 때 마다 의존관계 주입이 완료된 새로운 객체가 필요하면 사용하면 된다. 그런데 실무에서 웹 애플리케이션을 개발해보면, 싱글톤 빈으로 대부분의 문제를 해결할 수 있기 때문에 프로토타입 빈을 직접적으로 사용하는 일은 매우 드물다. ObjectProvider , JSR330 Provider 등은 프로토타입 뿐만 아니라 DL이 필요한 경우는 언제든지 사용할 수 있다.
스프링을 사용하다 보면 이 기능 뿐만 아니라 다른 기능들도 자바 표준과 스프링이 제공하는 기능이 겹칠때가 많이 있다. 대부분 스프링이 더 다양하고 편리한 기능을 제공해주기 때문에, 특별히 다른 컨테이너를 사용할 일이 없다면, 스프링이 제공하는 기능을 사용하면 된다.
웹 스코프
웹 스코프의 특징
- 웹 스코프는 웹 환경에서만 동작한다.
- 웹 스코프는 프로토타입과 다르게 스프링이 해당 스코프의 종료시점까지 관리한다. 따라서 종료 메서드가 호출된다.
웹 스코프 종류
- request: HTTP 요청 하나가 들어오고 나갈 때 까지 유지되는 스코프, 각각의 HTTP 요청마다 별도의 빈 인스턴스가 생성되고, 관리된다.
- session: HTTP Session과 동일한 생명주기를 가지는 스코프
- application: 서블릿 컨텍스트( ServletContext )와 동일한 생명주기를 가지는 스코프
- websocket: 웹 소켓과 동일한 생명주기를 가지는 스코프
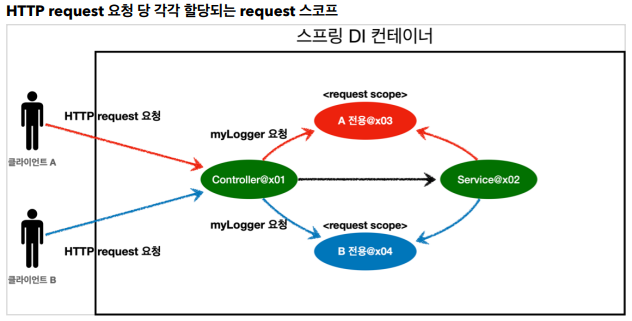
request 스코프 예제 개발
동시에 여러 HTTP 요청이 오면 정확히 어떤 요청이 남긴 로그인지 구분하기 어렵다. 이럴때 사용하기 딱 좋은것이 바로 request 스코프이다.
다음과 같이 로그가 남도록 request 스코프를 활용해서 추가 기능을 개발해보자.
[d06b992f...] request scope bean create
[d06b992f...][http://localhost:8080/log-demo] controller test
[d06b992f...][http://localhost:8080/log-demo] service id = testId
[d06b992f...] request scope bean close
기대하는 공통 포멧: [UUID][requestURL] {message}
UUID를 사용해서 HTTP 요청을 구분하자.
requestURL 정보도 추가로 넣어서 어떤 URL을 요청해서 남은 로그인지 확인하자.
MyLogger
@Component
@Scope(value = "request")
public class MyLogger {
private String uuid;
private String requestURL;
public void setRequestURL(String requestURL) {
this.requestURL = requestURL;
}
public void log(String message) {
System.out.println("[" + uuid + "]" + "[" + requestURL + "] " + message);
}
@PostConstruct
public void init() {
uuid = UUID.randomUUID().toString(); System.out.println("[" + uuid + "] request scope bean create:" + this);
}
@PreDestroy
public void close() {
System.out.println("[" + uuid + "] request scope bean close:" + this);
}
}
로그를 출력하기 위한 MyLogger 클래스이다. @Scope(value = "request") 를 사용해서 request 스코프로 지정했다.
이제 이 빈은 HTTP 요청 당 하나씩 생성되고, HTTP 요청이 끝나는 시점에 소멸된다. 이 빈이 생성되는 시점에 자동으로 @PostConstruct 초기화 메서드를 사용해서 uuid를 생성해서 저장해둔다.
이 빈은 HTTP 요청 당 하나씩 생성되므로, uuid를 저장해두면 다른 HTTP 요청과 구분할 수 있다. 이 빈이 소멸되는 시점에 @PreDestroy 를 사용해서 종료 메시지를 남긴다. requestURL 은 이 빈이 생성되는 시점에는 알 수 없으므로, 외부에서 setter로 입력 받는다.
LogConstructor
@Controller
@RequiredArgsConstructor
public class LogDemoController {
private final LogDemoService logDemoService;
private final MyLogger myLogger;
@RequestMapping("log-demo")
@ResponseBody
public String logDemo(HttpServletRequest request) {
String requestURL = request.getRequestURL().toString();
myLogger.setRequestURL(requestURL);
myLogger.log("controller test");
logDemoService.logic("testId"); return "OK";
}
}
로거가 잘 작동하는지 확인하는 테스트용 컨트롤러다. 여기서 HttpServletRequest를 통해서 요청 URL을 받았다. requestURL 값 http://localhost:8080/log-demo 이렇게 받은 requestURL 값을 myLogger에 저장해둔다. myLogger는 HTTP 요청 당 각각 구분되므로 다른 HTTP 요청 때문에 값이 섞이는 걱정은 하지 않아도 된다. 컨트롤러에서 controller test라는 로그를 남긴다.
참고: requestURL을 MyLogger에 저장하는 부분은 컨트롤러 보다는 공통 처리가 가능한 스프링 인터셉터나 서블릿 필터 같은 곳을 활용하는 것이 좋다. 여기서는 예제를 단순화하고, 아직 스프링 인터셉터를 학습하지 않은 분들을 위해서 컨트롤러를 사용했다. 스프링 웹에 익숙하다면 인터셉터를 사용해서 구현해보자
LogDemoService
@Service
@RequiredArgsConstructor
public class LogDemoService {
private final MyLogger myLogger;
public void logic(String id) {
myLogger.log("service id = " + id);
}
}
비즈니스 로직이 있는 서비스 계층에서도 로그를 출력해보자. 여기서 중요한점이 있다. request scope를 사용하지 않고 파라미터로 이 모든 정보를 서비스 계층에 넘긴다면, 파라미터가 많아서 지저분해진다. 더 문제는 requestURL 같은 웹과 관련된 정보가 웹과 관련없는 서비스 계층까지 넘어가게 된다. 웹과 관련된 부분은 컨트롤러까지만 사용해야 한다.
서비스 계층은 웹 기술에 종속되지 않고, 가급적 순수하게 유지하는 것이 유지보수 관점에서 좋다. request scope의 MyLogger 덕분에 이런 부분을 파라미터로 넘기지 않고, MyLogger의 멤버변수에 저장해서 코드와 계층을 깔끔하게 유지할 수 있다.
실제로 MyLogger는 스코프 범위가 request이므로 실행하면 오류가 발생한다.
이를 해결하기 위해서는 Provider 혹은 프록시를 사용한다.

ObjectProvider 덕분에 ObjectProvider .getObject()를 호출하는 시점까지 request scope 빈의 생성을 지연할 수 있다. ObjectProvider.getObject() 를 호출하시는 시점에는 HTTP 요청이 진행중이므로 request scope 빈의 생성이 정상 처리된
다.

스프링은 해당 클래스를 상속받은 가짜 프록시 객체를 생성한다. 프록시는 Provider과는 다르지만 작동은 유사하게 작동한다. 프록시 객체는 요청이 오면 그때 내부에서 진짜 빈을 요청하는 위임 로직이 들어있다.
특징
정리 프록시 객체 덕분에 클라이언트는 마치 싱글톤 빈을 사용하듯이 편리하게 request scope를 사용할 수 있다. 사실 Provider를 사용하든, 프록시를 사용하든 핵심 아이디어는 진짜 객체 조회를 꼭 필요한 시점까지 지연처리 한다는 점이다.
주의점
마치 싱글톤을 사용하는 것 같지만 다르게 동작하기 때문에 결국 주의해서 사용해야 한다. 이런 특별한 scope는 꼭 필요한 곳에만 최소화해서 사용하자, 무분별하게 사용하면 유지보수하기 어려워진다
'spring' 카테고리의 다른 글
| 스프링 테스트 통합해서 비용 줄이기(통합 테스트) (0) | 2024.07.09 |
|---|---|
| 객체 지향 설계와 스프링 (0) | 2023.03.05 |